
好久没写blog了,想起来把最近做的这个东西发上来,个人用起来还是很满意的
使用场景
下B站视频,要能最高画质,不然我大会员白开了,顺带直接存nas
前置准备
我们需要一个工具来解析视频的下载地址,而且要很方便不需要我单独去找一个软件来下,所以我就想到用浏览器拓展来干这个事情。猫抓(cat-catch)刚好是这么一个现成的流媒体抓取拓展,可以很方便的抓到B站的视频下载链接,同时还支持多端,在手机的edge同样可以使用。 注意到猫抓拓展还集成有数据发送的功能,即可以将抓取到的数据通过json格式发送到远程服务器,我想到可以在我的nas上部署一个这个服务器,就可以随时下载需要下载的视频了。
架构分析
可以知道的是,B站视频流分了两个文件,一个只传输视频,另一个只传输音频,所以下载的视频需要处理。为了服务的持久性,我不再将这个server放到我的本地电脑上而是移交到nas进行处理。 在此之前我们需要分析一下传递的json的结构:
{ "action": "", // 无用信息,忽略 "data": { "url": "", // 这里是解析到的下载url,关键 "referer": "", // 通常是"https://www.bilibili.com" "origin": "", // 同上 "initiator": "", // 同上 "webUrl": "", // 抓取源网页的url,含有Bv号的信息,关键 "title": "", // 抓取源网页的标题 "cookie": "", // 一般是空的,忽略 "tabId": $Id, // 标签页id "year": , "month": , "date": "", "day": "", "fullDate": "", "time": "", "hours": "", "minutes": , "seconds": , "now": , "timestamp": "", "fullFileName": "", // 完整文件名称 "fileName": "", // 文件名 "ext": "", // 文件后缀名 }, "tabId": "" // 和上面那个一样}为了保证不产生错误的音视频流匹配,我们需要充分利用浏览器拓展使用json为我们提供的信息,我使用的是标签页id,只有通过相同标签页发送的两个json才允许进行合并 另外,使用FIFO的数据结构对存入的json缓存 不过出于技术性考量,没有做更进一步的匹配设计,只要在客户端做正确的输入,基本上不会出现问题 另外,我让ai使用多线程进行操作,因为猫抓同时勾选两个进行发送,发送的是两次json,且几乎没有延时,需要分两个线程来处理不然会来不及接收丢包
代码组成
- 主函数多线程
def main(): with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind((HOST, PORT)) s.listen() print(f"Listening on port {PORT}...\n")
while True: conn, addr = s.accept() t = threading.Thread(target=handle_client, args=(conn, addr)) t.daemon = True t.start()- 接收处理json
def handle_client(conn, addr): print(f"Connected by {addr}") buffer = ""
with conn: while True: data = conn.recv(4096) if not data: break
buffer += data.decode('utf-8', errors='ignore') json_packet = extract_json(buffer) if json_packet: print(f"收到 JSON 来自 {addr}: {json_packet}")
process_incoming_json(json_packet)
buffer = "" # 清空,避免重复解析- 分析json数据,进行配对
def process_incoming_json(json_packet): """处理已解析的 JSON 包,同时执行 tabId 配对逻辑""" tabId = json_packet.get("tabId") data = json_packet.get("data") if tabId is None or data is None: print("收到 JSON 但缺少 tabId 或 data") return
# 只接受来自 https://www.bilibili.com 的 origin origin_val = data.get("origin") or data.get("originUrl") or data.get("Referer") or '' if origin_val != "https://www.bilibili.com": print(f"忽略非 B站来源(origin={origin_val}) tabId={tabId}") return
new_item = Item( tabId=tabId, data=data, timestamp=time.time() )
# 检查是否已有同 tabId 数据 if tabId in index: old_item = index.pop(tabId) # 从 pending 中移除旧 item for item in pending: if item.tabId == tabId: pending.remove(item) break # 成对数据 → 触发事件 handle_pair([old_item, new_item]) else: # 插入新数据 pending.append(new_item) index[tabId] = new_item print(f"已存入(等待配对) tabId={tabId}")- 配对数据后进行处理
def handle_pair(pair_list): # pair_list contains two Item objects (来自 process_incoming_json) left = pair_list[0] right = pair_list[1]
url1 = left.data.get("url") url2 = right.data.get("url") filename1 = left.data.get("fullFileName") filename2 = right.data.get("fullFileName") source = left.data.get("origin", "") title = left.data.get("title", "") subtitle = left.data.get("webUrl", "")
# 固定 Referer 为 bilibili,并强制使用默认 User-Agent;不发送 Origin headers_list = [ "Referer: https://www.bilibili.com", f"User-Agent: {DEFAULT_USER_AGENT}" ]
# 直接在后台线程下载两个文件并合并 t = threading.Thread(target=download_and_merge_thread, args=(url1, url2, filename1, filename2, title, subtitle, headers_list)) t.daemon = True t.start()- 下载视频到缓存文件夹并触发ffmpeg合并
def download_and_merge_thread(url1, url2, filename1, filename2, title, weburl, headers_list): """后台线程:依次下载两个文件并合并,合并后删除源文件。""" path1 = download_direct(url1, filename1, headers_list) path2 = download_direct(url2, filename2, headers_list) if not path1 or not path2: print("至少有一个下载失败,跳过合并") return
output_base = build_output_name(title, weburl) # 确保输出目录存在并写入到 OUTPUT_DIR try: os.makedirs(OUTPUT_DIR, exist_ok=True) except Exception as e: print(f"创建输出目录失败 {OUTPUT_DIR}: {e}") output_dir = os.getcwd() else: output_dir = OUTPUT_DIR
output_file_name = f"{output_base}.mkv" output_file = os.path.join(output_dir, output_file_name) ok = merge_with_ffmpeg(path1, path2, output=output_file) if ok: for p in (path1, path2): try: if os.path.exists(p): os.remove(p) print(f"已删除源文件: {p}") except Exception as e: print(f"删除文件失败 {p}: {e}")- ffpmeg合并音视频并保存到指定目录
def merge_with_ffmpeg(file_a, file_b, output=None): """使用 ffmpeg 将两个流合并(不转码,直接拷贝)。返回 True/False。 输出文件默认使用第一个文件名加后缀 `_merged.mkv`。 """ if output is None: base = os.path.splitext(file_a)[0] output = f"{base}_merged.mkv"
cmd = [ "ffmpeg", "-y", "-i", file_a, "-i", file_b, "-c", "copy", output ] try: print(f"运行 ffmpeg 合并: {' '.join(cmd)}") proc = subprocess.run(cmd, capture_output=True, text=True) if proc.returncode == 0: print(f"合并完成: {output}") return True else: print(f"ffmpeg 合并失败 (code={proc.returncode}): {proc.stderr}") return False except FileNotFoundError: print("ffmpeg 未找到,请先安装 ffmpeg 并确保其在 PATH 中。") return False这里提供了一份完整的代码供你自行配置 需要你自行填写保存路径哦
食用方法
在使用之前配置猫抓的数据发送功能,找到猫抓设置的数据发送part,按照python的设置配置端口(默认是17899),以及根据你远程服务的地址(本人使用内网ip),勾选手动发送,其他不用修改 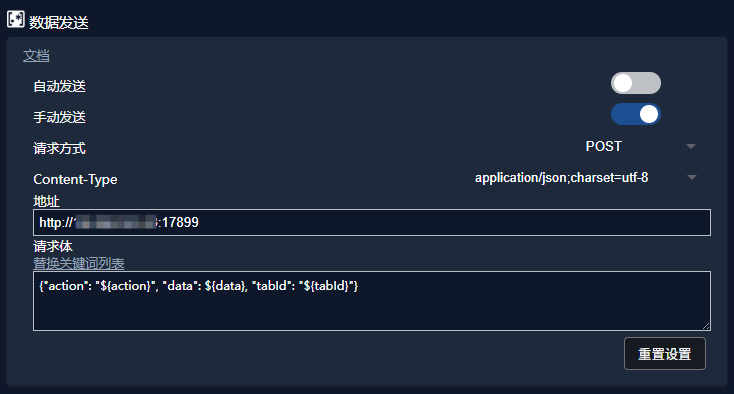
在你需要下载的视频打开猫抓拓展,选中音频流和视频流,通常是一个大文件和一个小文件。另外建议你在使用前刷新页面清除猫抓的缓存,保证不会抓到的是前一个视频的内容。随后点击更多功能 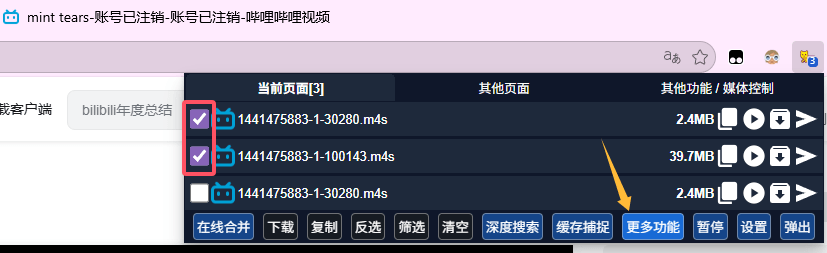 点击数据发送
点击数据发送 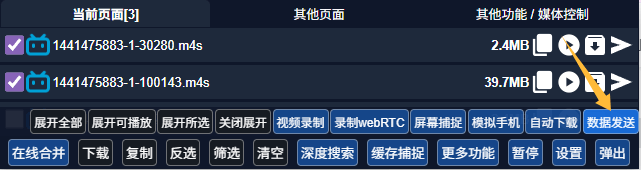 然后就将数据发送到下载设备上了
然后就将数据发送到下载设备上了
咕噜噜